So, you’re having an incident
This document is the GOV.UK PaaS team playbook for managing a technical incident. It covers tasks for the engineering lead and the communications (comms) lead.
Team roles
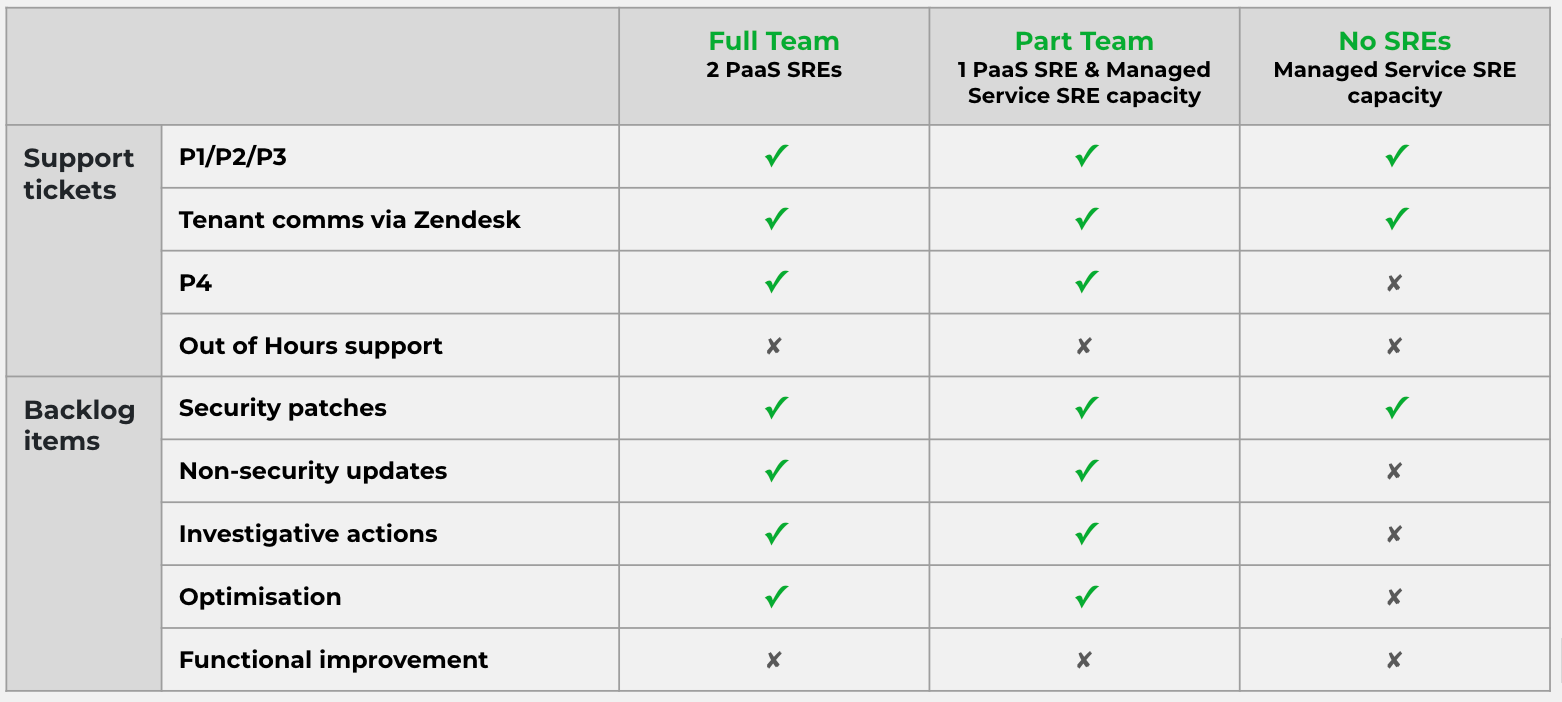
PaaS SREs: Full time SREs who work on the service day to day. Absences should be staggered to reduce the amount of time where neither PaaS SREs are available.
Managed Service SREs: Wider pool of SREs supplied via a managed service contract. Respond to incidents when neither PaaS SRE is available. Manage P1-P3 incidents only, using Team Manual runbook. Escalate to GDS backstop engineers if unable to mitigate the incident using the runbooks.
Engineering lead tasks
As the engineer on support, you become the engineering lead in an incident, and you’re responsible for declaring an incident. However, other engineers should help as necessary, especially in incidents lasting several hours or more.
As the engineering lead:
- you are responsible for investigating and resolving the issue, and reporting to the comms lead so they can communicate severity and timelines to stakeholders
- you are not expected to fix any underlying problems with our technology or processes – these will be discussed and addressed in an incident review
- you should be cautious if you’re unsure about what to do or what the impact of any action would be – the goal is to get the platform stable enough to be fixed by the PaaS SRE team
If you need help, other engineers can help you as needed. If you are unable to address the problem (even with the help of other engineers if available), you can raise a request for additional support in #paas-escalation. This should be used as a last resort only.
If an incident is ongoing outside of office hours (i.e. an in-hours incident continuing past 5pm), you should document progress on the ticket to ensure wider team context, and update tenants on progress and next steps.
Starting an incident
- Acknowledge the incident on PagerDuty or Slack and decide if the alerts you have received and their impact constitute an incident or not. Incidents generally have a negative impact on the availability of tenant services in some way or constitute a cyber security incident. Problems such as our billing smoke tests failing may indicate a tenant-impacting problem but do not in themselves constitute an incident.
- Document briefly which steps you are taking to resolve the incident in the #paas-incident Slack channel. If the situation impacts tenants, escalate to the person on communication (comms) support using PagerDuty or Slack so they can communicate with tenants.
- The #paas-incident channel has a bookmarked hangout link. Join this video call to communicate with the comms lead and talk through what you’re doing and what’s happening.
- If you decide it’s not an incident after investigating further, you must resolve the incident in PagerDuty. If you are sure it is an incident, agree on a priority for the incident with the comms lead. You can change this priority level later as more information emerges. Here are some upstream status links to check.
P4 Process
We do not have an SLA for P4s, as P4s are outside of scope for the Managed Service SREs. If the engineer on support is from the wider Managed Service Pool (and no PaaS SREs are available) then P4s will be paused until a PaaS SRE is available to investigate and remediate.
Communication lead tasks
You are not expected to be involved every time an alert goes off. PagerDuty will call the engineering lead in the event of an alert, and it is the engineering lead’s responsibility to triage and escalate to you as necessary.
As the comms lead, you communicate the status and impact of an incident to tenants and document what’s happening during the incident process.
- The #paas-incident Slack channel has a bookmarked hangout link. Join this video chat to communicate with the engineering lead, who will talk through what they’re doing and what’s happening. Record the actions the engineering lead takes and the times they happen.
- Create a new incident report using the incident report template, and fill it in with the information you currently have. Save the incident report in the incident reports folder on the PaaS shared drive.
- Begin populating the timeline with the notes the engineer has left in #paas-incident, if there are any.
- Work with the engineering lead to agree a priority for the incident.
- Ask for periodic updates (every 20-30 minutes) from the engineer(s) handling the technical side of the incident. You should draft and issue comms appropriate to the update time for the severity level. This is described in our documentation on response times for services in production. Our primary communication channel with tenants during an incident is StatusPage. If a tenant contacts you on Slack or through another channel, politely ask them to wait for updates through StatusPage.
You should write incident comms in plain English and focus on what impact tenants can expect rather than what is wrong. For example, choose “end users are likely to experience intermittent interruption” rather than “one of the availability zones is down”.
If an incident is ongoing outside of office hours across the boundary between in and out of office hours (i.e.for example, an in-hours incident continuing past 5pm or an out-of-hours incident continuing past 9am), you should update StatusPage with progress and next steps.
If you have been involved in an out-of-hours incident, you are not required to work until 11 hours after the end of the incident.
Cyber security incidents
If the engineering and comms leads suspect the incident may need to involve the Cyber Security team, the incident can be escalated to the Cyber Security team. To escalate to the Cyber Security team you can call the phone number listed under Cyber Security on the PagerDuty Live Call Routing addons page. You can also email the Cyber Security team reporting address, or use the #cyber-security-help Slack channel.
Examples of cyber security incidents include:
- unauthorised access to tenant apps and backing services
- unauthorised access to platform infrastructure
- exploitation of vulnerabilities in platform APIs
See the appendix on what qualifies as a cyber security incident for more information.
As per our shared responsibility model, we are not responsible for the code tenants deploy. As a result, we are not responsible for spotting, preventing, or mitigating cyber security incidents within their services. However, we may spot exploitation of a vulnerability in a tenant service in our logs, at which point we should inform the tenant and give them the information we have.
After an incident is resolved
Once an incident is resolved:
- the comms lead should make sure they have communicated the resolution in all the same channels that they first communicated the incident in – this will primarily be StatusPage
- the delivery manager or one of the incident leads should schedule an incident review as soon as it is reasonably possible for as many concerned parties as possible to attend, ideally within 1-2 weeks
Long-running incidents
It is possible that an incident will run across multiple days – for example, an incident might not be resolved before the end of the working day. In this case, you need to ensure progress on the incident is documented to allow fresh engineering and comms leads to commence work the following day, mitigating the risk that you are out of office and work cannot proceed.
When to consider pausing and documenting
You should start the process to document an incident if:
- you are working on an incident in office hours and the time has reached 5pm
- you have been working on an incident for a long stretch of time (6 hours should be the maximum)
How to pause and document
- The comms lead should check the incident report has a summary of the incident and is up-to-date.
- The comms lead should share the incident report with the PaaS SREs and wider managed service pool for visibility.
- An incident continuation meeting should be scheduled for 9am the following working day to talk through:
- the current incident status
- any useful contextual information
- the status of any communications that need to be updated further
Escalation paths
In hours
Use the #paas-internal Slack channel to contact other team members.
If you need to contact SMT, talk to the person on the Product and Technology (P&T) SMT escalation rota in PagerDuty.
Out of hours
There is no out of hours provision for this service.
Service provider support details
AWS
Log into AWS and raise a support ticket.
We have denial-of-service (DoS) protection as part of our AWS contract. You can contact the team through the standard support channel.
Aiven
Raise a ticket through the Aiven console, or email support@aiven.io. We do not have a support package with Aiven, so they cannot guarantee response times.
Appendix
What qualifies as a cyber security incident?
We follow the NCSC’s definition of what constitutes a cyber incident. For our team, this means:
- unauthorised access to non-public data of GOV.UK services
- exploitation of a vulnerability or lack of access control to use or alter GOV.UK services and systems
- denial-of-service (DoS) or similar attacks on GOV.UK services
For an incident to be considered a cyber security incident, it should be an active breach and/or involve exposure of data rather than these issues just being a hypothetical possibility. For example, if we discover that some GOV.UK PaaS software has a vulnerability with a low likelihood of exploitation, we would not consider it a cyber security incident. However, if we learned that an attacker had access to GOV.UK PaaS tenant data, we would consider it a cyber security incident.
If you’re in doubt about whether to declare a cyber security incident, you can seek help by escalating.
Upstream Status Pages and Channels
Here are a few places to check for potential upstream failures.
Cloud Foundry Slack (Join the #general for discussions on outages or incidents.)
Defining an incident priority
Our incident priorities are publicly documented on our product pages.